Étudier les véhicules polluants en ville
| Projet | Durée | Difficulté | Âge |
|---|---|---|---|
| SteamCity | 4 heures | Intermédiaire | 10-15 ans |
Matériel
- 1 jeu de cartes « Numéro »
- 1 jeu de cartes « Dataset de véhicules » par groupe
- 1 feuille d'algorithme par groupe
- Jeu de cartes « Numéro »
- Jeu de cartes « Dataset de véhicules »
- Feuille d'algorithme (tableau de condition de séparation à remplir)

Introduction
Le protocole « Trees VS Cars » vise à offrir aux élèves une introduction accessible à l'apprentissage supervisé, un concept fondamental de l'apprentissage automatique et de l'intelligence artificielle. Grâce à une activité pratique en classe, les élèves approfondiront leur compréhension de la manière dont les ordinateurs peuvent apprendre à prendre des décisions en fonction de modèles de données.
Derrière cet objectif général, les élèves exploreront comment les machines peuvent classer l'information en apprenant à partir d'exemples plutôt qu'en suivant des règles explicitement programmées. Cette approche permet aux ordinateurs de s'adapter à de nouvelles situations et de faire des prédictions basées sur des expériences antérieures – un peu comme l'apprentissage humain, mais grâce à des processus mathématiques et statistiques.
À travers les phases du protocole, les élèves créeront un modèle capable de catégoriser les véhicules en deux groupes : ceux autorisés à circuler dans la ZBE de Bruxelles et ceux qui ne le sont pas, sur base de trois critères : le type de véhicule, le type de carburant et l'année de fabrication.
Cette application spécifique – la classification des véhicules pour la Zone de Basses Émissions (ZBE) de Bruxelles – représente une mise en œuvre concrète de l'IA existante dans les systèmes de gestion urbaine, démontrant comment les villes utilisent des systèmes intelligents pour réguler le trafic et réduire la pollution. La technologie d'arbre de décision que les élèves exploreront est déployée dans diverses applications de ville intelligente, de l'optimisation des itinéraires des transports publics à la prévision des besoins en maintenance des infrastructures urbaines.
Structure du protocole
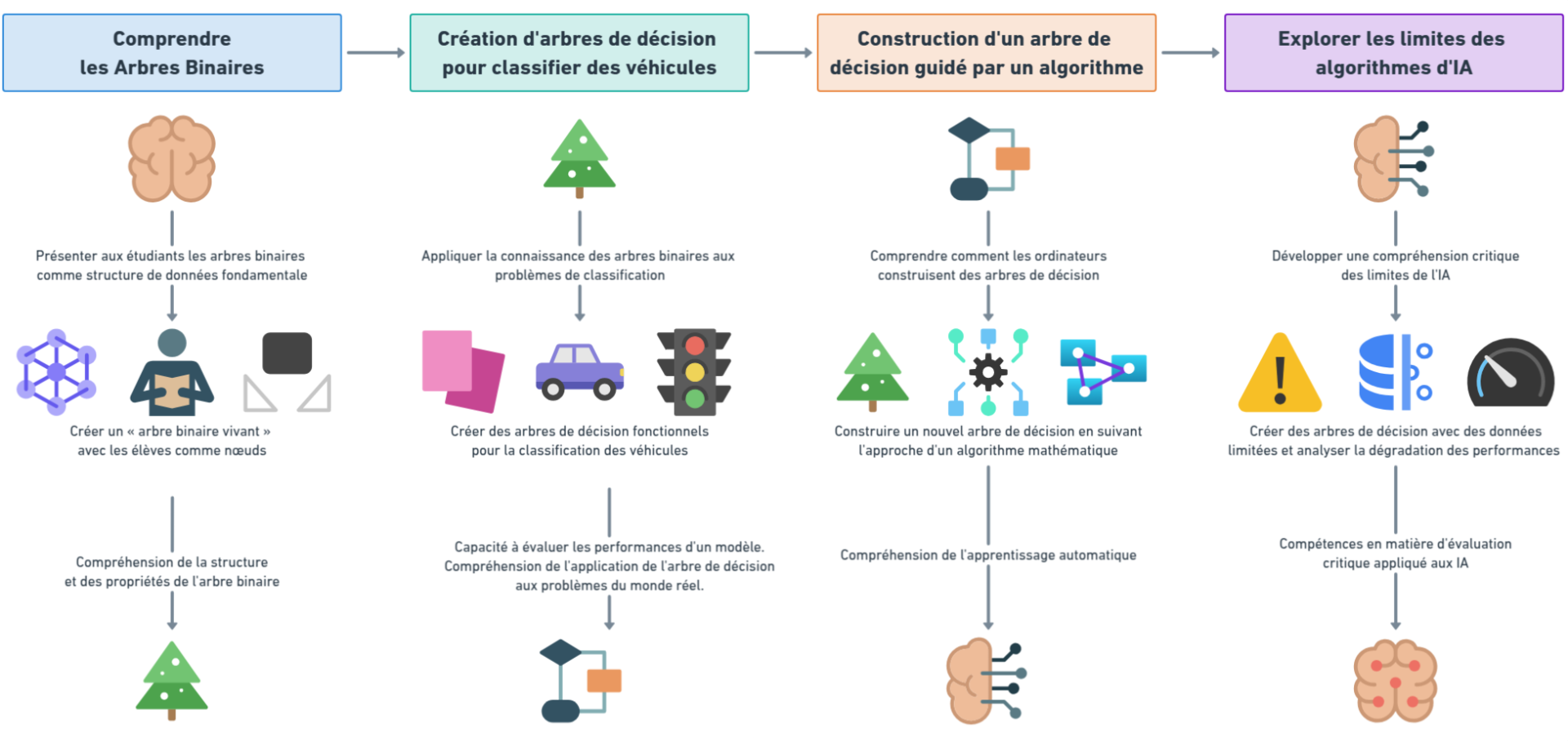
Dans le protocole « Trees VS Cars », les élèves suivront une méthodologie en 4 phases structurée comme suit :
- Phase 1 : Comprendre les arbres binaires. Les élèves découvriront le concept d'arbres binaires, une structure de données largement utilisée dans le domaine de l'apprentissage supervisé.
- Phase 2 : Création d'arbres de décision pour la classification des véhicules. Les élèves construiront un arbre de décision, une forme particulière d'arbre binaire, afin de séparer un ensemble de véhicules en deux catégories : ceux autorisés à circuler dans la ZBE de Bruxelles et les autres. Ils compareront les arbres créés et leur performance dans la catégorisation des véhicules.
- Phase 3 : Construction d'un arbre de décision guidé par un algorithme. En s'appuyant sur les connaissances acquises, les élèves construiront un nouvel arbre de décision, en suivant cette fois un algorithme qui leur sera fourni. Ils compareront ensuite les arbres créés et leurs performances entre eux et avec les arbres de décision créés précédemment.
- Phase 4 : Explorer les limites des algorithmes d'IA. Afin d'ouvrir une discussion plus large sur les systèmes d'IA et de conclure sur le protocole, cette dernière phase incitera les élèves à découvrir certaines des principales limites de ce type d'algorithme, leur montrant que l'IA n'est pas un outil magique capable de résoudre n'importe quel problème, mais plutôt un moyen très efficace de résoudre certains types de problèmes.
Glossaire
- Arbre binaire : un arbre binaire est une structure de données dans laquelle chaque élément (appelé nœud) possède au maximum deux nœuds enfants et au maximum un nœud parent. Les nœuds sans enfants sont appelés les « feuilles » de l'arbre.
- Apprentissage automatique : l'apprentissage automatique (ML) est un domaine d'étude de l'intelligence artificielle qui s'intéresse au développement et à l'étude d'algorithmes statistiques capables d'apprendre à partir de données et de généraliser sur des données inédites, et ainsi d'effectuer des tâches sans instructions explicites.
- Apprentissage supervisé : l'apprentissage supervisé est une technique d'apprentissage automatique qui utilise des ensembles de données étiquetés pour former des modèles d'algorithmes d'intelligence artificielle afin d'identifier les patterns et les relations sous-jacents entre les caractéristiques d'entrée et les sorties.
- Modèle : le modèle est le résultat du processus d'apprentissage. C'est lui qui permet de faire des prédictions sur de nouvelles données.
- Généralisation : la généralisation est la capacité du modèle à prédire correctement de nouvelles données, non utilisées pendant la formation.
- Performances du modèle : la performance du modèle est la mesure de la capacité d'un modèle à faire des prédictions correctes.
Phase 1 : Comprendre les arbres binaires
Contexte de la séquence
Les arbres binaires sont une structure de données omniprésente en informatique. Ils présentent de nombreuses propriétés intéressantes, telles que l'efficacité de la recherche, de l'insertion et de la suppression d'éléments, et la capacité de représenter des expressions mathématiques pour l'analyse syntaxique dans les compilateurs. Ils sont également utilisés dans les algorithmes de compression de données, comme le codage de Huffman. La compréhension du concept d'arbre binaire est essentielle dans ce protocole, car l'arbre de décision des phases suivantes est une forme particulière d'arbre binaire.
Objectifs d'apprentissage
Comprendre le concept d'arbres binaires.
Conceptualisation
Pour comprendre comment un ordinateur peut prendre une décision, il est nécessaire de comprendre comment il organise les données d'entrée. Commençons par examiner comment les humains ont structuré et organisé de grands volumes d'informations, ainsi que les méthodes utilisées pour les extraire. L'exemple le plus simple est celui des dictionnaires. Un dictionnaire est un livre contenant les définitions des mots, classées par ordre alphabétique. Cette organisation facilite la recherche. Il n'est pas nécessaire de parcourir tout le dictionnaire. En identifiant la première lettre du mot recherché, vous pouvez ouvrir directement à une page approximative où il pourrait se trouver. En fonction des mots présents sur cette page, il est possible de déterminer si la recherche doit se poursuivre avant ou après, éliminant ainsi un grand nombre de pages. Ce processus est ensuite répété jusqu'à localiser le mot recherché.
Cette méthode est connue sous le nom de recherche dichotomique. Un autre exemple de cette approche est le jeu consistant à deviner un nombre compris entre 1 et 100. La meilleure stratégie consiste à diviser le champ des possibilités en deux parties égales, puis à éliminer l'une des deux moitiés. La structure utilisée pour la recherche dichotomique est un arbre binaire. Dans cette phase, les élèves découvriront comment ils l'emploient déjà.
Investigation par les élèves
Les élèves découvriront le concept d'arbre binaire à l'aide d'arbres binaires de recherche. L'objectif est de créer un arbre binaire humain, chaque élève représentant un nœud.
Pour commencer, chaque élève reçoit une carte numérotée aléatoirement entre 1 et le nombre d'élèves (vous pouvez utiliser les cartes numérotées en annexe, ou simplement utiliser des morceaux de papier numérotés).
L'enseignant choisit au hasard un élève pour devenir la racine de l'arbre. Cet élève annonce le numéro reçu, et le reste de la classe est divisé en deux : ceux dont le numéro est le plus bas se placent à gauche, les autres à droite. Ce processus est répété jusqu'à ce que tous les élèves soient placés, formant ainsi un arbre complet où chaque « feuille » représente un élève.
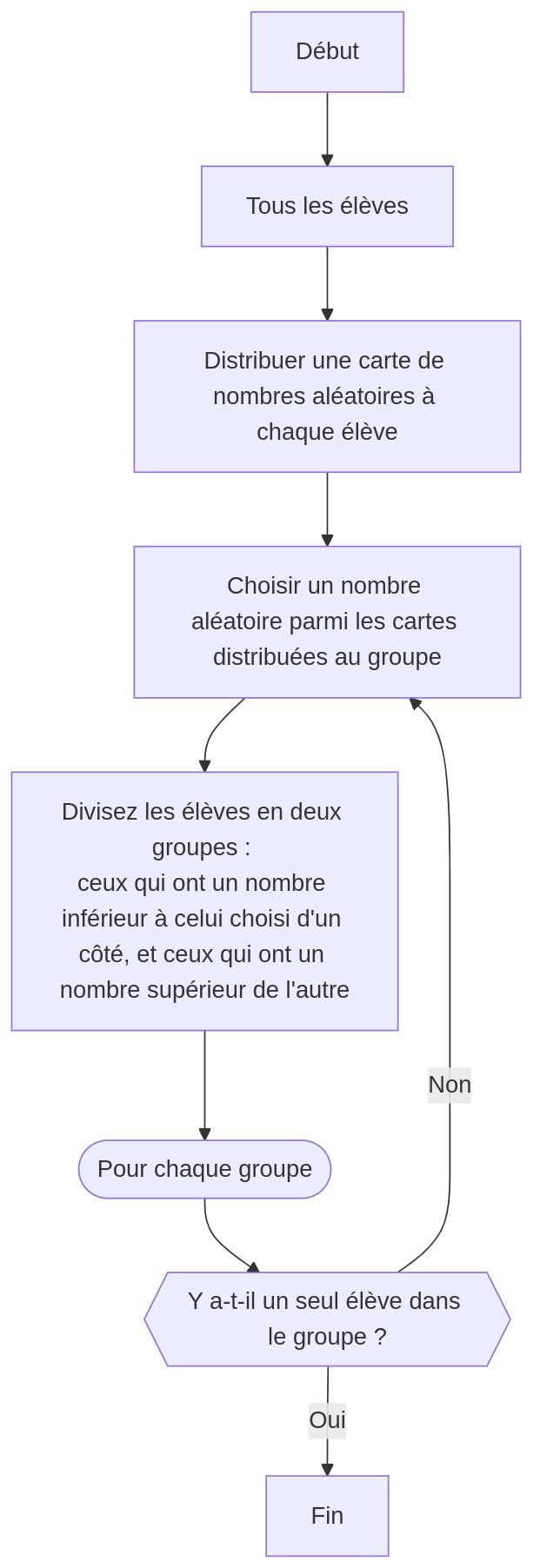
Pour bien comprendre l'organisation des données dans un arbre binaire, l'enseignant choisit un élève au hasard parmi les feuilles de l'arbre. La classe doit ensuite parcourir l'arbre pour identifier le numéro de chaque élève. Les élèves doivent comprendre qu'ils viennent de créer un arbre binaire, et plus précisément un arbre binaire de recherche, c'est-à-dire un arbre binaire dont la particularité est d'être très efficace pour la recherche au sein des données.
Les élèves apprendront ensuite à équilibrer l'arbre qu'ils ont créé. Pour ce faire, l'enseignant divisera la classe en groupes et distribuera les cartes numériques de manière équitable entre ces groupes (environ dix cartes par groupe). Les élèves devront construire un arbre binaire, comme précédemment, mais cette fois-ci, ils tenteront de créer l'arbre le plus efficace.
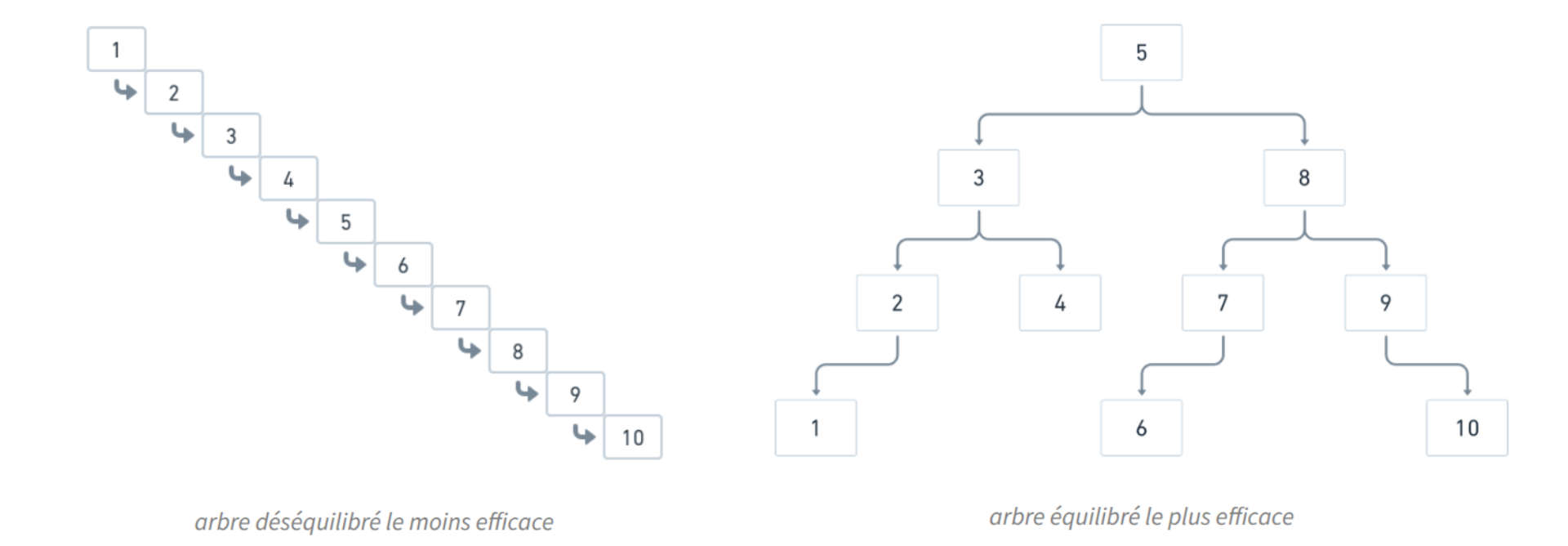
Pour créer un arbre optimal, il faut essayer de trouver l'arbre ayant les branches les plus courtes possibles. Si les élèves ont du mal à saisir le concept, l'enseignant peut demander aux groupes qui éprouvent des difficultés de créer d'abord l'arbre le moins efficace, c'est-à-dire celui ayant les branches les plus longues possibles. En comprenant comment construire l'arbre le moins efficace, les élèves devraient mieux comprendre comment en trouver un meilleur.
L'arbre le moins efficace est celui qui ne contient qu'une seule branche, où les nombres sont classés par ordre (arbre déséquilibré). En revanche, l'arbre le plus efficace est complètement équilibré, c'est-à-dire que toutes les branches de l'arbre ont la même longueur (plus ou moins 1).
Restitution et réflexion
- Connaissances mobilisées : Les élèves ont exploré le concept d'arbres binaires grâce à une activité pratique. Ils ont compris la structure de l'arbre et son efficacité dans la recherche de données en expérimentant la création d'arbres efficaces et inefficaces.
- Réflexion sur la mise en œuvre en classe : Les élèves ont participé activement à la construction d'un arbre de recherche binaire en se positionnant dans la classe selon un ordre numérique. Grâce à une réflexion guidée, ils ont compris le concept d'arbres plus efficaces et l'importance d'équilibrer les branches pour minimiser la profondeur de recherche.
- Résultats d'apprentissage : Les élèves ont acquis une compréhension fondamentale des arbres binaires et des arbres de recherche binaire. Ils ont appris à apprécier l'importance des arbres équilibrés pour une recherche de données efficace et à développer des compétences en résolution de problèmes pour optimiser les structures arborescentes.
Phase 2 : Création d'arbres de décision pour la classification des véhicules
Contexte de la séquence
Après avoir découvert le concept d'arbre binaire, les élèves verront dans quelle mesure les arbres binaires peuvent être utilisés pour l'apprentissage automatique, en particulier la classification des données.
Objectifs d'apprentissage
Comprendre ce qu'est un arbre de décision. Apprendre à utiliser un arbre de décision pour classer les données et faire des prédictions. Apprendre à mesurer la performance d'un modèle.
Conceptualisation
Une fois le concept d'arbre binaire maîtrisé, la structure de données créée et étudiée à la phase 1 peut être enrichie et complexifiée pour aider les décideurs. Cette structure est appelée arbre de décision. Au lieu de stocker des nombres, chaque nœud est une question fermée. Chaque élève d'un nœud représente une réponse possible (généralement « oui » ou « non »). Les feuilles symbolisent le résultat du processus de décision.
Tout comme les arbres binaires, qui permettent d'éliminer rapidement de nombreux éléments d'une recherche, un arbre de décision évite les questions inutiles et accélère le processus de prise de décision.
Dans cette phase du protocole, les élèves appliqueront leurs connaissances à la construction d'un arbre de décision plus complexe pour déterminer quel véhicule est autorisé ou non dans une ZBE. Dans les zones urbaines du monde entier, les zones à faibles émissions (ZBE) se multiplient, les villes s'efforçant de réduire la pollution atmosphérique et d'améliorer la santé publique. Ces zones restreignent l'accès aux véhicules en fonction de leurs niveaux d'émissions, garantissant ainsi que seuls ceux qui respectent certaines normes environnementales peuvent y entrer. Comprendre les critères d'entrée des véhicules est crucial pour les urbanistes et les propriétaires de véhicules. Comment utiliser un arbre de décision pour déterminer si un véhicule est autorisé ou non à entrer dans une ZBE ?
Investigation par les élèves
Au cours de cette phase, les élèves devront se familiariser avec un jeu de données, représenté par le jeu de cartes de véhicules. Description des éléments visuels des cartes :
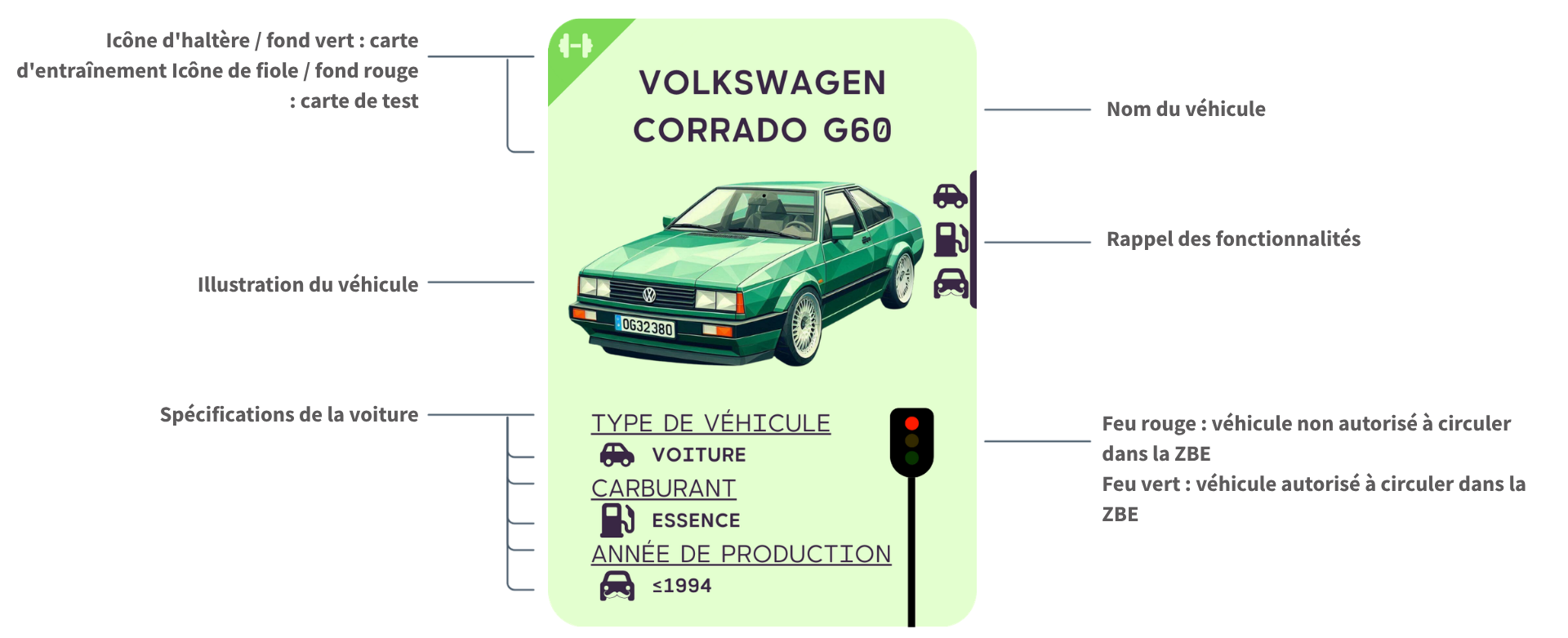
- Icône d'haltère / fond vert : carte d'entraînement
- Icône de fiole / fond rouge : carte de test
- Nom du véhicule et illustration
- Rappel des fonctionnalités et spécifications
- Feu rouge : véhicule non autorisé à circuler dans la ZBE
- Feu vert : véhicule autorisé à circuler dans la ZBE
Pour chaque véhicule, il y a 3 caractéristiques avec 3 valeurs possibles :
| Type de véhicule | Type de carburant | Date de fabrication |
|---|---|---|
| Voiture | Essence | ≤ 1994 |
| Utilitaire | Diesel | 1995–2006 |
| Moto | Électrique | > 2006 |
Chaque véhicule possède également une étiquette, représentée par le feu tricolore en bas à droite de la carte.
Après s'être familiarisés avec les cartes, les élèves travailleront en groupes pour construire un arbre de décision en utilisant uniquement les cartes d'entraînement (les cartes de test seront utilisées ultérieurement). Pour ce faire, les élèves devront suivre les étapes suivantes à chaque nœud de l'arbre de décision :
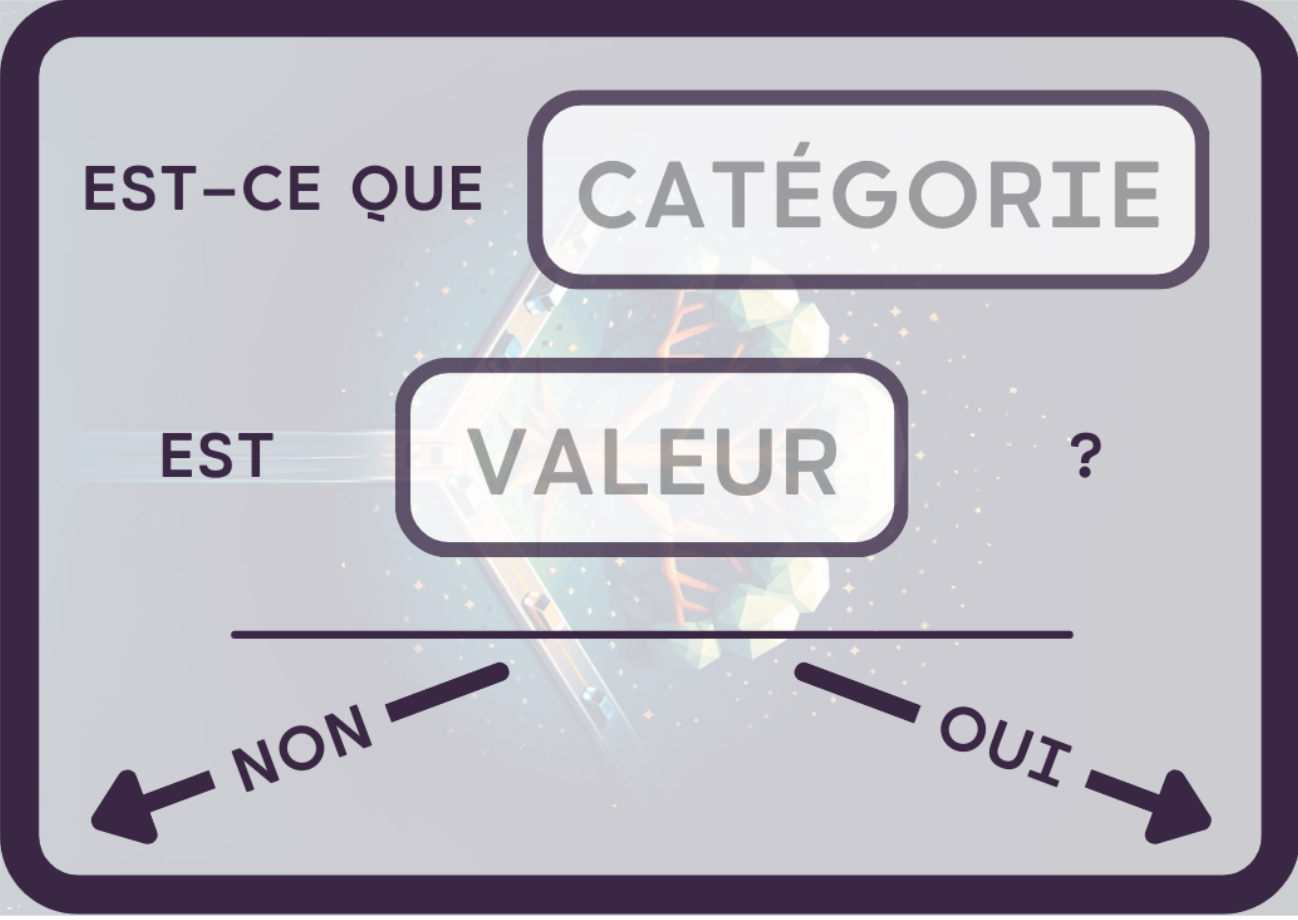
- Choisir une condition de séparation sous la forme : « Est-ce que [catégorie] est [valeur] ? » Par exemple : « Est-ce que le carburant est de type diesel ? » et enregistrer la question sur l'une des fiches de questions fournies.
- Diviser les cartes de véhicules en deux groupes selon que chaque véhicule répond vrai ou faux à cette condition, et les répartir de chaque côté de la carte de question.
- Continuer le processus pour chaque nouveau groupe formé, en choisissant de nouvelles conditions.
- Arrêter lorsqu'un groupe ne contient que des véhicules autorisés dans la ZBE (feu vert) ou que des véhicules non autorisés (feu rouge).
Pour évaluer la performance de leur modèle, les élèves utiliseront des cartes de test. Ils déplaceront chaque carte vers le bas de leur arbre de décision, en suivant les conditions à chaque nœud, jusqu'à atteindre une feuille. Si l'étiquette (feu tricolore) de la carte correspond à celle de la feuille atteinte, la prédiction est considérée comme correcte. Les élèves comptent le nombre de prédictions correctes, puis divisent ce nombre par le nombre total de cartes testées. Le résultat, exprimé en pourcentage, indique la précision du modèle. Plus le score est proche de 100 %, meilleur est le modèle. Cette méthode permet aux élèves d'évaluer objectivement la capacité de leur arbre à prendre des décisions correctes sur de nouvelles données.
Enfin, les groupes compareront leurs arbres et leurs performances. Il peut être intéressant de leur demander quelle méthode ou stratégie ils ont utilisée pour choisir la condition de séparation des données à chaque nœud.
Restitution et réflexion
- Connaissances mobilisées : Les élèves ont exploré le concept d'arbres binaires et leur application en apprentissage automatique, notamment en classification de données. Ils ont appris les fondamentaux des arbres de décision, leur structuration et les méthodes d'évaluation de leurs performances prédictives.
- Réflexion sur la mise en œuvre en classe : Grâce à des activités pratiques, les élèves ont construit des arbres de décision à partir d'un jeu de données de cartes de véhicules, définissant les conditions de séparation et organisant les données de manière itérative. La réflexion a consisté à tester leurs modèles avec des données inédites, à calculer la précision et à comparer les stratégies et les résultats avec leurs pairs.
- Résultats d'apprentissage : Les élèves ont acquis une compréhension des arbres de décision comme outils d'aide à la décision, développant ainsi leur esprit critique pour structurer efficacement les données. Ils ont amélioré leurs compétences en science des données en mesurant la précision des modèles et en apprenant à évaluer l'impact de leurs choix de conception sur les performances.
Phase 3 : Construction d'un arbre de décision guidé par algorithme
Contexte de la séquence
À la phase précédente, les élèves ont créé un arbre de décision. Pour ce faire, ils ont choisi la condition de séparation à utiliser pour chaque branche. Cependant, un ordinateur ne peut prendre de décisions arbitraires et doit s'appuyer sur des outils statistiques et mathématiques pour analyser les données. Les élèves créeront donc un nouvel arbre de décision, mais cette fois en utilisant une méthode permettant de déterminer la meilleure condition de séparation pour chaque branche.
Objectifs d'apprentissage
Comprendre comment un ordinateur construit un arbre de décision efficace. Identifier la méthode la plus efficace pour choisir la condition de séparation.
Conceptualisation
À la phase précédente, les participants ont exploré la définition de critères de séparation permettant de déterminer, à chaque étape, si un véhicule est autorisé ou non à entrer dans la ZBE. Selon les groupes, les questions posées et les approches adoptées étaient différentes. Bien que le résultat final puisse être le même, il est essentiel de se demander s'il existe une solution (ou un algorithme) capable d'identifier les meilleurs critères pour prendre une décision de manière fiable et rapide.
Investigation par les élèves
Durant cette phase, les élèves construiront un nouvel arbre de décision comme dans la phase précédente, mais en suivant une méthode très précise pour déterminer la condition à choisir à chaque nœud.
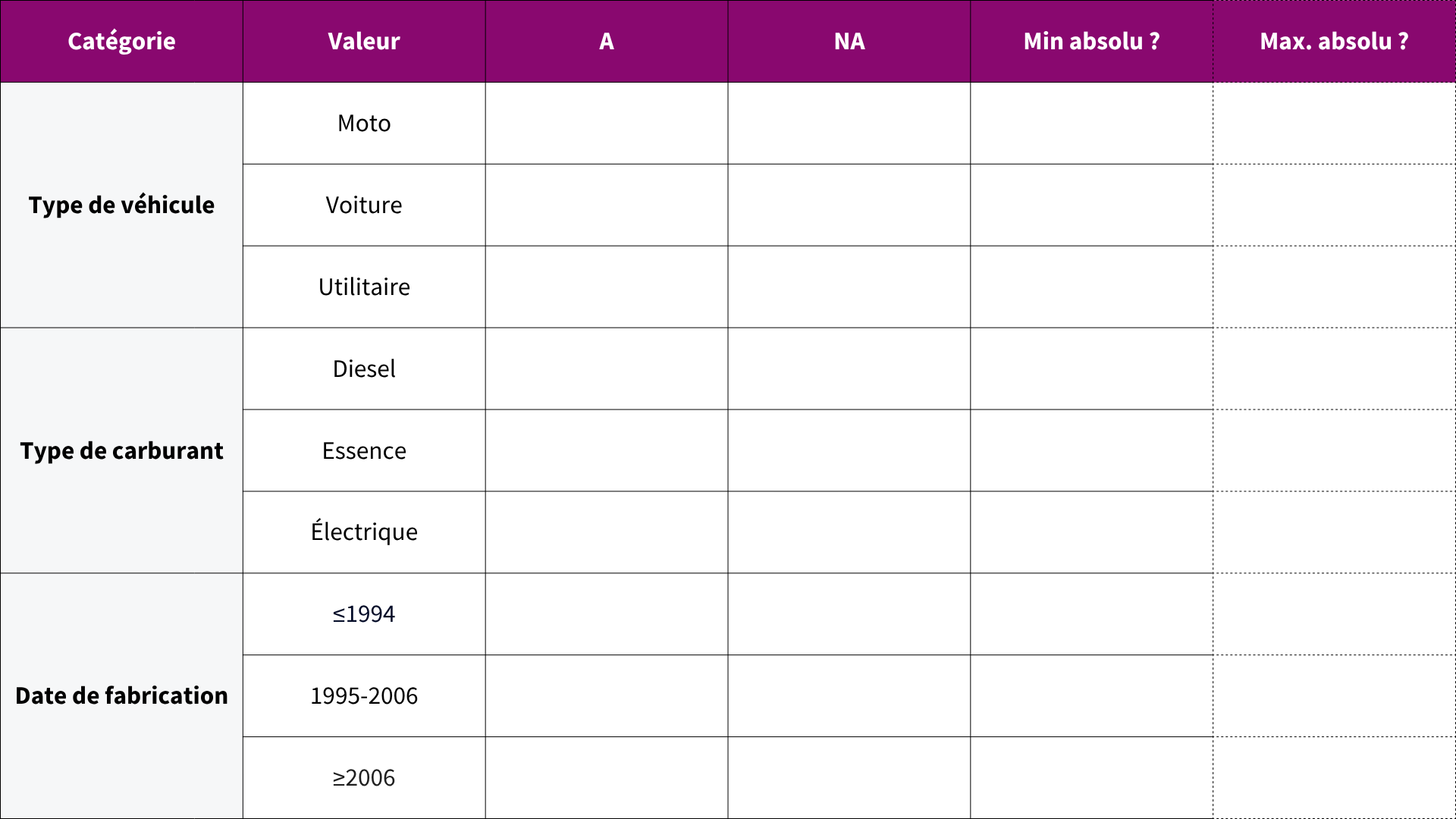
Pour les guider, les élèves disposeront du tableau suivant, qui peut être plastifié pour une utilisation répétée ou imprimé en plusieurs exemplaires (6 à 8). Il permet de déterminer la meilleure condition de séparation pour les véhicules :
| Catégorie | Valeur | A | NA | Min. absolu ? | Max. absolu ? |
|---|---|---|---|---|---|
| Type de véhicule | Moto | ||||
| Type de véhicule | Voiture | ||||
| Type de véhicule | Utilitaire | ||||
| Type de carburant | Diesel | ||||
| Type de carburant | Essence | ||||
| Type de carburant | Électrique | ||||
| Date de fabrication | ≤ 1994 | ||||
| Date de fabrication | 1995–2006 | ||||
| Date de fabrication | ≥ 2006 |
Étapes pour trouver la meilleure condition de séparation :
- Remplir les colonnes A et NA (véhicules autorisés et non autorisés) pour chaque valeur de chaque catégorie.
- Identifier la valeur minimale. Identifier la ou les lignes présentant la plus petite valeur dans la colonne A ou NA. Cocher la case correspondante dans la colonne MIN ABSOLU ?.
- Identifier la valeur maximale. À partir de la ou des lignes où MIN ABSOLU ? est coché, identifier la ou les lignes avec la valeur la plus élevée de A ou NA, et cocher la case MAX ABSOLU ? en conséquence.
- Choisir la condition optimale. La condition de séparation optimale est celle correspondant à la ligne dont les cases sont cochées à la fois dans MIN ABSOLU ? et MAX ABSOLU ?.
Le reste du processus est identique à la phase précédente. Le résultat sera l'organigramme disponible ici : bit.ly/binarytreeiafrsvg (format Mermaid : bit.ly/binarytreeiafrsource). Si les élèves exécutent correctement l'algorithme, ils devraient tous obtenir le même arbre de décision. Lors des tests, ils devraient également obtenir les meilleures performances.
Restitution et réflexion
- Connaissances mobilisées : Les élèves ont exploré le processus décisionnel informatique. Ils ont appris à appliquer un algorithme structuré pour créer des arbres de décision cohérents et efficaces.
- Réflexion sur la mise en œuvre en classe : Grâce à des activités pratiques, les élèves ont suivi un algorithme détaillé pour construire des arbres de décision basés sur une analyse statistique des caractéristiques des ensembles de données.
- Résultats d'apprentissage : Les élèves ont acquis une compréhension des processus décisionnels informatiques et développé des compétences pour appliquer des algorithmes à la classification des données. Ils ont amélioré leur capacité à analyser méthodiquement des ensembles de données et ont reconnu l'importance de la précision dans les processus d'apprentissage automatique.
Phase 4 : Explorer les limites des algorithmes d'IA
Contexte de la séquence
Les élèves ont appris à construire et à utiliser un arbre de décision. Cette phase vise à montrer certaines limites inhérentes à l'apprentissage automatique.
Objectifs d'apprentissage
Découvrir certaines des limites de ces algorithmes.
Conceptualisation
Dans le cadre de ce protocole, les arbres de décision apparaissent comme un outil particulièrement adapté, offrant la possibilité d'obtenir rapidement une réponse. Cependant, comme toute méthode de représentation, ils présentent des limites et un champ d'application au-delà duquel leur efficacité diminue. À cette phase, les élèves analysent et explorent les limites inhérentes à cette structure. Ils examinent également la qualité des données utilisées pour construire l'arbre et l'impact que ces données peuvent avoir sur la précision et la fiabilité des prédictions produites par cette structure.
Investigation par les élèves
Les élèves découvriront d'abord la principale limitation applicable à tous les algorithmes d'apprentissage automatique : la taille du jeu de données d'entraînement. Pour ce faire, ils créeront un nouvel arbre de décision, mais cette fois en supprimant la moitié des cartes d'entraînement, soit six cartes. À l'exception de quelques groupes potentiellement chanceux, les élèves devraient obtenir un arbre moins performant que celui créé à la phase 3. L'enseignant demandera ensuite aux élèves pourquoi l'arbre obtenu est moins performant, afin de leur faire comprendre qu'en supprimant des données, l'algorithme manque d'exemples et de cas nécessaires pour faire des choix pertinents.
Ensuite, les élèves construiront un arbre de décision final, cette fois en intervertissant les cartes d'entraînement et les données de test. Ils devraient alors tous obtenir le même arbre qui génère des erreurs de prédiction. Comme pour l'arbre précédent, l'enseignant leur demandera pourquoi l'arbre est moins performant que celui de la phase 3. Ici, contrairement à l'arbre précédent, il y a encore plus de données d'entraînement que de cartes de test ! Les élèves doivent comprendre que la quantité de données n'est pas tout. En effet, si les données d'entraînement ne sont pas représentatives de toutes les données possibles, l'algorithme d'entraînement pourrait accorder plus ou moins d'importance à certains critères que ce n'est réellement le cas pour toutes les données possibles. Pour cette activité, les données d'entraînement ont été soigneusement sélectionnées afin de maximiser les performances du modèle, mais il est assez rare qu'un modèle fasse des prédictions correctes dans 100 % des cas. Il est possible d'approcher cette valeur, mais très difficile, voire impossible, de l'atteindre.
Restitution et réflexion
- Connaissances mobilisées : Les élèves ont abordé les limites fondamentales des algorithmes d'apprentissage automatique, en se concentrant sur deux aspects clés : l'insuffisance des données d'entraînement et la représentativité des ensembles de données. Ils ont développé une réflexion critique sur les raisons pour lesquelles les arbres de décision peuvent échouer dans certaines conditions.
- Réflexion sur la mise en œuvre en classe : Grâce à des expériences, les élèves ont créé et évalué des arbres de décision avec des données de formation réduites et des ensembles de données non représentatifs.
- Résultats d'apprentissage : Les participants ont appris à identifier et à expliquer les limites des arbres de décision et des algorithmes d'apprentissage automatique en général. Ils ont compris l'importance d'ensembles de données équilibrés et représentatifs, améliorant ainsi leur capacité à évaluer de manière critique la fiabilité des modèles prédictifs.
Ressources
Livres et guides
- "Machine Learning: An Algorithmic Perspective" par Marsland, S. — Présente les algorithmes derrière les arbres de décision, avec une approche pratique.
- "Data Mining: Practical Machine Learning Tools and Techniques" par Witten, I. H., Frank, E., Hall, M. A., & Pal, C. J. — Un livre pratique qui explique comment mettre en œuvre des arbres de décision à l'aide d'outils modernes.
- "Data Mining with Decision Trees: Theory and Applications" par Rokach, L., & Maimon, O. — Un livre spécialisé sur les arbres de décision, couvrant les fondements théoriques et les applications pratiques.
Ressources en ligne
- Mermaid — Outil en ligne permettant de créer des diagrammes et des schémas à l'aide d'une syntaxe textuelle simple. Particulièrement utile aux développeurs et aux chefs de projet qui souhaitent présenter visuellement des processus complexes de manière claire et efficace.
- Chapter 3.2 BINARY SEARCH TREES, Algorithme par Robert Sedgewick, Kevin Wayne.
Annexe : Planche de cartes véhicules
- Planche complète du jeu de cartes « Dataset de véhicules » à imprimer et découper.

Cette fiche fait partie du projet SteamCity, financé par le programme Erasmus+. Contenu sous licence CC BY-SA 4.0.