Comprendre les processus d'apprentissage bio-inspirés
| Projet | Durée | Difficulté |
|---|---|---|
| SteamCity | Trois séances d'environ 45 minutes | Modéré |
Matériel
- Une grille imprimée 6x6
- Un marqueur pour indiquer la position actuelle
- Un ordinateur ou une tablette pour accéder à l'outil en ligne BioLearningGame
- Des tableaux blancs pour des discussions collaboratives

Introduction
L'apprentissage est l'un des processus fondamentaux que partagent les humains et les machines, même si les mécanismes peuvent être très différents. Dans cette activité, les élèves se lanceront dans un voyage exploratoire pour découvrir comment une machine apprend et le comparer à leurs propres processus d'apprentissage. En participant à des exercices pratiques, ils comprendront à la fois les défis et les méthodes de l'apprentissage par essais et erreurs, et observeront comment les commentaires, positifs ou négatifs, peuvent favoriser l'amélioration.
L'objectif de cette activité est de fournir aux élèves une compréhension intuitive des modèles d'apprentissage bio-inspirés et de la façon dont les machines, à l'instar des organismes vivants, utilisent la méthode des essais et des erreurs pour s'adapter et trouver des solutions. En établissant des parallèles entre leurs propres stratégies d'apprentissage et celles des machines, les élèves comprendront comment l'intelligence artificielle tente d'imiter les processus d'apprentissage naturels.
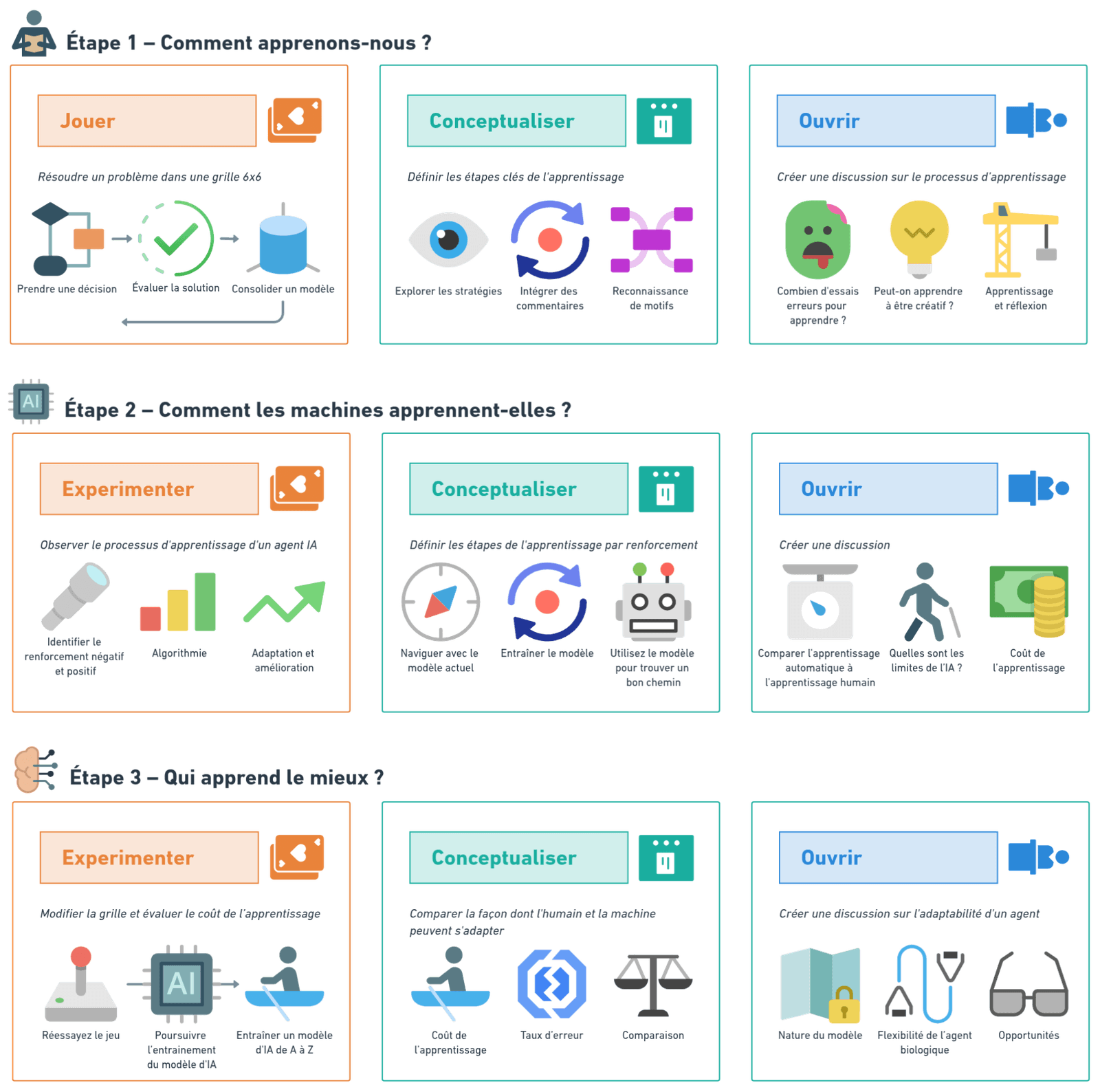
L'activité se décompose en trois étapes distinctes, chacune offrant une expérience immersive et pratique d'apprentissage par l'expérimentation. Ces étapes démontreront la nature itérative de l'apprentissage et mettront l'accent sur la valeur de l'adaptabilité, une caractéristique clé nécessaire pour devenir un véritable agent autonome dans la ville. À la fin de l'activité, les élèves devraient avoir une meilleure compréhension des principes de l'apprentissage par renforcement, de la résolution de problèmes par essais-erreurs et des différences d'adaptabilité entre les humains et les machines.
Structure de l'activité
L'activité se déroulera en trois étapes principales, chacune conçue pour introduire progressivement les élèves au concept d'apprentissage bio-inspiré. Vous trouverez ci-dessous un aperçu de la structure de l'expérience :
- Découvrir l'apprentissage humain à travers un jeu débranché : Les élèves participeront à un jeu utilisant une grille 6x6 et un point qu'ils doivent déplacer. Ils peuvent déplacer le point dans l'une des quatre directions (haut, bas, gauche, droite), et chaque déplacement entraîne soit une victoire, une défaite ou une continuation en fonction des commentaires de l'enseignant. L'objectif, qui n'est pas initialement révélé, est que les élèves trouvent le point gagnant. Ils le découvriront par des essais et des erreurs répétés, puis tenteront de trouver le chemin le plus court.
- Découvrez comment l'apprentissage automatique fonctionne : les élèves utiliseront un outil en ligne appelé BioLearningGame (https://charly-sketch.github.io/DiscoverAI/PlayerLearningGame/PlayerBiolearning.html) pour observer comment une IA tente de résoudre le même problème. Comme les élèves, l'ordinateur n'a aucune connaissance préalable de l'objectif et doit utiliser la méthode des essais et des erreurs pour découvrir le bon chemin. Cette étape présente aux élèves le concept de modèles d'apprentissage automatique, d'apprentissage par renforcement et de rétroaction positive et négative.
- Adaptabilité des humains par rapport aux machines : À cette étape, les élèves compareront leur adaptabilité à celle de l'IA. Ils se diviseront en deux groupes : l'un modifiera la carte de la ville et l'autre devra naviguer à travers les changements sans voir la carte. Pendant ce temps, le modèle informatique tentera d'apprendre l'environnement modifié. L'objectif est de comparer la rapidité et l'efficacité avec lesquelles les humains et les machines s'adaptent au nouvel environnement.
À la fin de l'activité, la discussion sera ouverte pour considérer avec les élèves les impacts positifs de l'IA dans leur vie quotidienne et leur avenir ainsi que pour identifier ses limites.
Glossaire
- Adaptabilité : Capacité à s'adapter à de nouvelles conditions ou à des changements dans l'environnement. Dans le contexte de cette activité, cela fait référence à la manière dont les humains et l'IA peuvent ajuster leur comportement pour atteindre un objectif lorsque les circonstances changent.
- IA (Intelligence Artificielle) : La capacité d'une machine à imiter le comportement humain intelligent, comme l'apprentissage par l'expérience, l'adaptation à de nouvelles données et l'exécution de tâches sans intervention humaine.
- Apprentissage bio-inspiré : Modèles d'apprentissage inspirés des processus naturels observés dans les organismes biologiques. Il s'agit d'une adaptation par essais et erreurs, similaire à la façon dont les animaux et les humains apprennent.
- Retour : Informations sur le comportement d'une personne ou d'une machine pouvant être utilisées pour l'améliorer. Les commentaires positifs encouragent la répétition du comportement, tandis que les commentaires négatifs découragent les actions indésirables.
- Modèle d'apprentissage : Système ou algorithme utilisé pour apprendre à partir de données ou d'expériences. En IA, il désigne la méthode par laquelle la machine met à jour ses connaissances pour améliorer ses actions.
- Renforcement négatif : Le processus d'apprentissage en recevant des conséquences négatives pour des actions incorrectes, réduisant ainsi la probabilité de répéter ces actions.
- Renforcement positif : Le processus d'apprentissage consistant à recevoir des récompenses pour des actions correctes, augmentant ainsi la probabilité de répéter ces actions.
- Q-Apprentissage : Un type d'algorithme d'apprentissage par renforcement qui permet à une IA d'apprendre à naviguer dans un environnement en équilibrant l'exploration et l'exploitation de ses connaissances actuelles.
- Apprentissage par renforcement : Un type d'apprentissage automatique dans lequel un agent apprend à prendre des décisions en effectuant des actions et en recevant des récompenses ou des pénalités.
- Essai et erreur : Une méthode d'apprentissage de base dans laquelle un individu ou une machine essaie différentes actions jusqu'à en trouver une qui mène à un résultat positif.
- Itération : La répétition d'un processus afin d'atteindre un objectif souhaité. Dans le contexte de l'apprentissage automatique, cela fait référence à la répétition du cycle d'apprentissage pour améliorer les performances.
Étape 1 : Découvrir l'apprentissage humain grâce à un jeu débranché
Contexte de la séquence
Dans cette première étape, les élèves participeront à un jeu formel conçu pour les aider à comprendre le concept d'apprentissage par essais et erreurs sans connaissance préalable de l'objectif. Le jeu utilise une grille 6x6 dans laquelle les élèves doivent déplacer un point de repère dans l'une des quatre directions. Chaque mouvement entraînera une rétroaction (gagner, perdre ou continuer). Ce processus aide les élèves à comprendre la dynamique de l'apprentissage lorsque l'objectif n'est pas explicitement connu.
Objectifs d'apprentissage
- Compétences de base : Comprendre l'apprentissage par essais et erreurs, développer des compétences en résolution de problèmes et améliorer l'adaptabilité pour atteindre un objectif caché.
- Compétences auxiliaires : Développer la conscience spatiale, l'apprentissage collaboratif par le biais de discussions de groupe et l'optimisation de stratégie de base pour trouver le chemin le plus court.
Conceptualisation
Durant cette étape, les élèves joueront à un jeu pour découvrir et explorer le concept d'apprentissage par l'essai à travers une approche ludifiée. Afin de lancer le jeu, voici le déroulement typique d'une séquence. Les élèves disposent d'une grille 6x6 (soit dessinée au tableau de la classe, soit imprimée pour être utilisée en petits groupes ou individuellement) et d'un marqueur de points.

Ils doivent déplacer le marqueur dans l'une des quatre directions possibles (haut, bas, gauche ou droite) et créer un itinéraire pour trouver leur objectif de point final, c'est-à-dire un endroit précis sur la grille.




L'enseignant jouera le rôle d'« environnement », en donnant un retour après chaque mouvement :
- « Continuer » : Les élèves peuvent continuer à se déplacer pour tenter de trouver l'objectif.
- « Perdre » : Les élèves ont heurté un obstacle ou emprunté un mauvais chemin et ils doivent recommencer depuis le début.
- « Gagner » : Les élèves ont atteint l'objectif et le jeu se termine.
Le principal défi est que les élèves ne savent pas quel est l'objectif ni où il se situe. À force de tentatives répétées et d'expérience, ils commenceront à élaborer des stratégies, à apprendre de leurs erreurs précédentes et, finalement, à identifier le point cible. Une fois qu'ils auront découvert l'objectif, les élèves s'efforceront alors de trouver le chemin le plus court pour l'atteindre efficacement.
Pour garantir un engagement efficace au cours de cette session, envisagez différentes approches en fonction du cadre de la classe et du temps disponible :
- Démonstration en classe entière : vous pouvez utiliser le jeu comme une tâche de groupe, en dessinant une grande grille de 6 x 6 sur le tableau et en demandant à un élève de déplacer le point en fonction des instructions données par ses camarades. Cela rend l'activité interactive et favorise la collaboration.
- Exercice individuel : Donnez à chaque élève sa propre grille et son propre marqueur pour qu'il puisse tenter l'activité de manière autonome. Cela peut être utilisé s'il y a suffisamment de temps et que vous souhaitez voir comment chaque élève aborde la résolution de problèmes sans l'influence du groupe.
- Activité en petits groupes : divisez les élèves en groupes de 4 à 6 et fournissez à chaque groupe sa propre grille imprimée de 6 x 6 pouces et un marqueur de points. Chaque groupe peut travailler ensemble pour déterminer les déplacements, favorisant ainsi une collaboration à petite échelle.
Adaptez la méthode en fonction de la taille de la classe, des contraintes de temps et du niveau d'engagement des élèves. L'utilisation d'une combinaison d'approches peut aider à maintenir l'intérêt et à offrir des perspectives différentes sur le processus de résolution de problèmes.
Investigation par les élèves
Une fois que le contexte du jeu, les règles et le matériel (selon le cadre choisi) ont été dévoilés aux élèves, vous pouvez commencer à jouer jusqu'à ce que les élèves trouvent le bon itinéraire pour atteindre le point gagnant. Une fois le jeu terminé, l'enseignant lancera une discussion sur la façon dont les élèves ont abordé le problème :
- Quelles stratégies ont-ils utilisées pour explorer la grille ?
- Comment ont-ils géré les situations « perdantes » et quelles adaptations ont-ils faites ?
- Comment ont-ils identifié l'objectif et trouvé le chemin le plus court ?
Les élèves seront encouragés à réfléchir à l'importance de l'apprentissage par essais et erreurs et par itérations. Ils comprendront que chaque échec fournit des informations précieuses qui les aident à affiner leurs tentatives futures.
L'enseignant doit également inciter les élèves à réfléchir au moment où ils ont commencé à comprendre l'objectif :
- À quel moment ont-ils commencé à reconnaître des modèles dans les commentaires fournis ?
- Quand ont-ils senti qu'ils se rapprochaient de l'identification de la cible ?
- Comment leur compréhension a-t-elle évolué, passant de mouvements aléatoires initiaux à des décisions plus ciblées ?
L'objectif est de démontrer que l'apprentissage est un processus itératif dans lequel les erreurs constituent une part essentielle de l'acquisition de connaissances. En discutant de ces aspects, les élèves comprendront comment leurs stratégies ont changé au fil du temps, quels moments précis les ont aidés à comprendre l'objectif et comment ils pourraient optimiser leur approche une fois l'objectif identifié.
Restitution et réflexion
Dans cette étape, les élèves ont participé à un jeu qui leur demandait d'apprendre par essais et erreurs sans connaissance préalable de l'objectif. L'objectif était d'illustrer comment l'apprentissage peut être réalisé de manière progressive en utilisant le feedback pour s'adapter et s'améliorer. L'enseignant peut utiliser le site BioLearning (https://charly-sketch.github.io/DiscoverAI/PlayerLearningGame/PlayerBiolearning.html) pour montrer une solution aux élèves dont la grille n'a pas été révélée.
- Connaissances mobilisées : À la fin de cette étape, les élèves auront développé une compréhension concrète de l'apprentissage par essais et erreurs. Ils apprendront à adapter leurs stratégies en réponse aux commentaires et se rendront compte que la recherche d'une solution nécessite souvent plusieurs tentatives.
- Réflexion sur la mise en oeuvre en classe : Ce jeu favorise également le travail d'équipe et la communication. Les élèves collaboreront probablement, partageront leurs découvertes et suggéreront des stratégies les uns aux autres. Il est important de souligner que le partage des connaissances peut contribuer à accélérer le processus d'apprentissage.
- Résultats d'apprentissage généraux : Les étudiants apprécieront mieux la valeur de l'apprentissage itératif et de l'adaptabilité, des compétences cruciales non seulement pour l'apprentissage humain mais aussi pour comprendre comment les machines, comme les modèles d'IA, apprennent par essais et erreurs.
Discutez de la façon dont le fait d'apprendre à naviguer dans la grille sans la voir leur a permis de construire une sorte de « modèle mental » de l'environnement. Cette notion de « modèle appris » sera essentielle à l'étape suivante, où ils observeront comment une machine construit son propre modèle pour résoudre le même problème.
À la fin de cette étape, révélez aux élèves que la grille représentait une ville, le point symbolisait une ambulance et l'objectif était d'atteindre l'hôpital. Expliquez-leur qu'ils ont reçu un minimum d'informations pour les empêcher d'utiliser leurs connaissances préalables, simulant ainsi la manière dont une machine apprend sans biais préexistants. Discutez de la façon dont la navigation dans la grille invisible leur a permis de construire un « modèle mental » de l'environnement. Présentez le concept d'apprentissage par renforcement en expliquant comment les succès ont renforcé positivement leur modèle – en indiquant le bon chemin – tandis que les échecs l'ont renforcé négativement en mettant en évidence les zones à éviter. Soulignez que les retours positifs et négatifs étaient essentiels pour développer une stratégie efficace. Cette notion de « modèle appris » sera essentielle à l'étape suivante, où les élèves observeront comment une machine construit son propre modèle pour résoudre le même problème.
Pour conclure cette étape, les élèves participeront à une discussion centrée sur des questions ouvertes. Ces questions sont conçues pour encourager une réflexion plus approfondie sur l'exercice et ses implications plus larges. Voici dix exemples de questions qui pourraient être discutées :
- Comment votre approche pour trouver l'objectif a-t-elle évolué à mesure que vous avez reçu davantage de commentaires ?
- Quelles émotions avez-vous ressenties lorsque vous avez dû tout recommencer après avoir perdu, et comment ces sentiments ont-ils influencé votre stratégie ?
- Dans quelle mesure était-il crucial de vous souvenir de vos mouvements précédents lorsque vous essayiez de trouver le but ?
- De quelle manière la collaboration avec vos camarades de classe a-t-elle amélioré votre compréhension de l'objectif ?
- Comment s'est déroulée votre navigation sans connaître l'objectif par rapport à votre expérience après avoir appris l'emplacement de l'hôpital ?
- Quelles similitudes pensez-vous exister entre les défis auxquels vous avez été confrontés et ceux rencontrés par les machines lors de ce type d'apprentissage ?
- Comment pensez-vous que le processus d'essais et d'erreurs améliore votre capacité à résoudre de nouveaux problèmes dans la vie réelle ?
- Quels ont été les moments clés qui vous ont fait réaliser que vous vous rapprochiez du but ?
- Comment pensez-vous que le concept de construction d'un « modèle mental » s'applique à d'autres matières ou tâches que vous apprenez ?
- De quelle manière cette expérience pourrait-elle vous aider à comprendre les limites de l'apprentissage humain et automatique ?
Étape 2 : Découvrez comment les machines apprennent
Contexte de la séquence
Dans cette deuxième étape, les élèves exploreront comment une machine apprend à l'aide d'un outil en ligne. L'objectif est d'établir un parallèle entre leur propre expérience d'apprentissage par essais et erreurs et la façon dont un système d'intelligence artificielle aborde le même problème, en soulignant les similitudes et les différences. L'objectif est que les élèves comprennent comment l'IA utilise une approche systématique de l'apprentissage, en s'appuyant uniquement sur des commentaires sans aucune connaissance ou intuition préexistante, tout comme leur expérience initiale. En comparant l'apprentissage humain et l'apprentissage automatique, les élèves observeront également comment le processus itératif diffère entre les êtres vivants et les modèles informatiques, en se concentrant sur l'efficacité et les défis de chaque approche.
Objectifs d'apprentissage
- Compétences de base : Comprendre les bases de l'apprentissage automatique et de l'apprentissage par renforcement, observer comment les machines apprennent de l'expérience et comprendre comment le feedback affecte l'apprentissage dans les systèmes d'IA. Les étudiants découvriront également les différents éléments de renforcement (à la fois positifs et négatifs) et comment ceux-ci contribuent à la construction d'un modèle d'apprentissage pour la machine.
- Compétences auxiliaires : Apprendre à observer et à comparer de manière critique l'apprentissage humain et l'apprentissage automatique, comprendre comment le renforcement positif et négatif affecte l'apprentissage, commencer à voir comment les modèles d'IA sont construits de manière itérative et apprécier la puissance de l'apprentissage informatique dans le traitement rapide de grandes quantités de données pour affiner les résultats d'apprentissage.
Conceptualisation
À cette étape, les élèves utiliseront l'outil en ligne BioLearningGame pour observer comment un agent IA tente de résoudre le même problème sur lequel ils ont travaillé à l'étape 1. L'IA commence sans aucune connaissance préalable de l'objectif, tout comme les élèves de la première étape. Elle doit apprendre en se déplaçant dans la grille et en recevant des commentaires pour chaque action :
- Renforcement positif : lorsque l'IA fait un mouvement correct, elle reçoit un retour positif, renforçant les actions qui la rapprochent de l'objectif. Cela ressemble à la satisfaction que ressentaient les élèves à la première étape lorsqu'ils trouvaient un mouvement qui fonctionnait bien, les poussant dans la bonne direction.
- Renforcement négatif : les mouvements incorrects entraînent un retour négatif que l'IA utilise pour comprendre les chemins à éviter à l'avenir. Tout comme la frustration ou le contretemps ressenti par les élèves lorsqu'ils font un mauvais mouvement, l'IA ajuste son modèle pour réduire la probabilité de répéter les erreurs.
L'enseignant expliquera que le modèle d'apprentissage de l'IA, appelé modèle d'apprentissage par renforcement, s'inspire de l'approche par essais et erreurs. En observant l'IA, les élèves verront comment elle apprend progressivement à trouver le chemin optimal vers la cible au travers d'échecs et de réussites répétés. Ce processus reflète l'apprentissage humain mais à un niveau plus systématique et informatique.
Pour aider les élèves à comprendre plus concrètement l'apprentissage par renforcement, l'enseignant peut fournir un exemple en utilisant un système de notation. Pour chaque mouvement correct, l'IA reçoit une récompense de 1 point. Lorsque l'IA atteint l'objectif, elle gagne une récompense importante de 100 points. Si l'IA rencontre un obstacle, elle reçoit une pénalité de -10 points. L'IA utilise ces récompenses et pénalités pour mettre à jour son modèle de l'environnement, un processus appelé Q-Learning.
L'algorithme Q-Learning met à jour son modèle en utilisant la formule suivante :
Q(état, action) = Q(état, action) + taux d'apprentissage * (récompense + facteur d'actualisation * max(Q(état suivant, toutes les actions)) - Q(état, action))
Où :
- Q(état, action) : utilité attendue d'une action donnée à partir d'un état donné.
learning_rate: paramètre qui contrôle la quantité de nouvelles informations qui remplacent les anciennes.- récompense : récompense immédiate reçue après avoir effectué l'action.
discount_factor: facteur qui détermine l'importance des récompenses futures par rapport aux récompenses immédiates.- max(Q(
next_state,all_actions)) : récompense future maximale attendue pouvant être atteinte à partir de l'état suivant.
Par exemple, si l'IA se déplace vers une nouvelle position et reçoit une récompense de 1 point, la valeur Q de cette paire état-action est mise à jour pour refléter cette nouvelle information. Si l'IA heurte un obstacle et reçoit une pénalité de -10 points, elle apprend à éviter ce chemin à l'avenir en abaissant la valeur Q de cette action. Cependant, avec cette fonction de notation, le robot peut ne pas donner la priorité à la recherche du chemin le plus court puisque chaque mouvement normal a une valeur positive. Pour garantir que le robot recherche le chemin le plus court, une fonction de notation pourrait inclure une pénalité mineure pour chaque mouvement, comme -1 point par mouvement, une pénalité de -100 points pour avoir heurté un obstacle et une récompense de 100 points pour avoir atteint l'objectif. Cela encourage l'IA à minimiser les mouvements inutiles tout en visant à atteindre l'objectif. Le processus se poursuit de manière itérative, chaque action affinant le modèle.
L'enseignant peut également illustrer que chaque action de l'IA est motivée par sa tentative de maximiser sa récompense cumulative, en essayant d'obtenir autant de renforcement positif que possible tout en minimisant le retour négatif. Il s'agit d'une approche itérative où chaque étape est soit un moment d'apprentissage, soit un renforcement d'actions réussies précédentes. Ce concept permet d'introduire la façon dont les machines utilisent les expériences pour s'améliorer, sans l'intuition sur laquelle les humains s'appuient souvent.
Investigation par les élèves
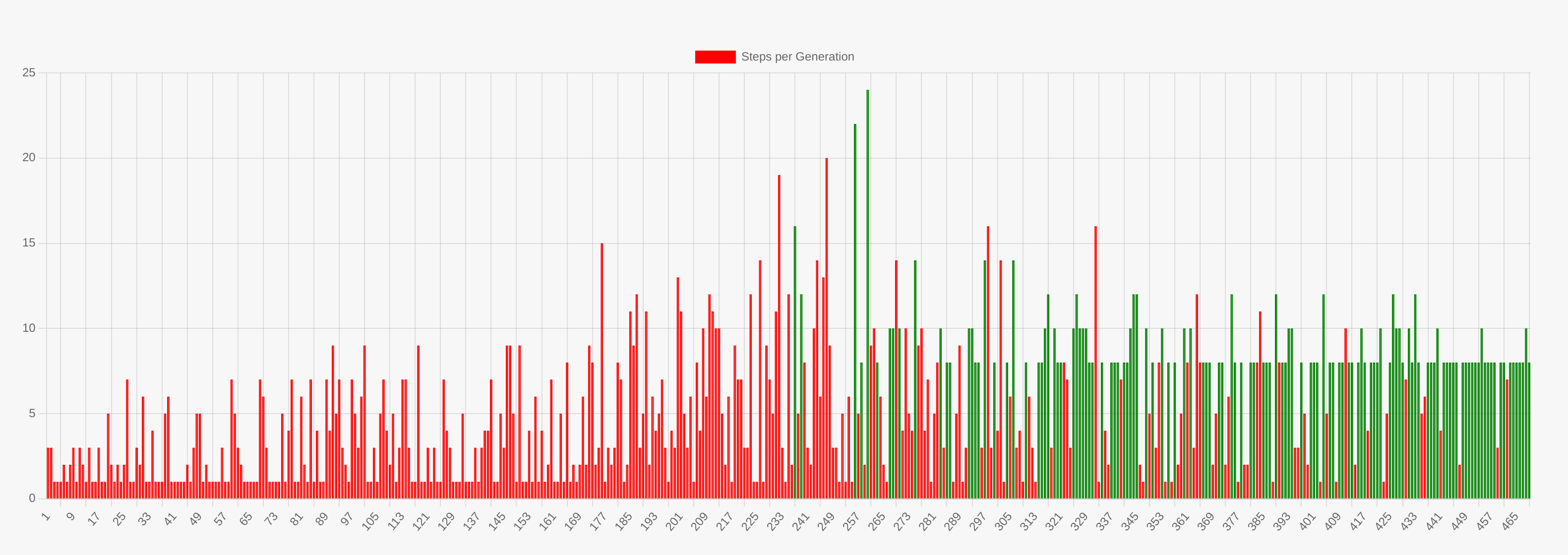
Au cours de la phase d'investigation, les élèves observeront et analyseront activement le comportement d'apprentissage de l'IA sur l'application BioLearning. Ils peuvent utiliser le graphique situé sous le plateau de jeu pour comprendre le processus global d'apprentissage.
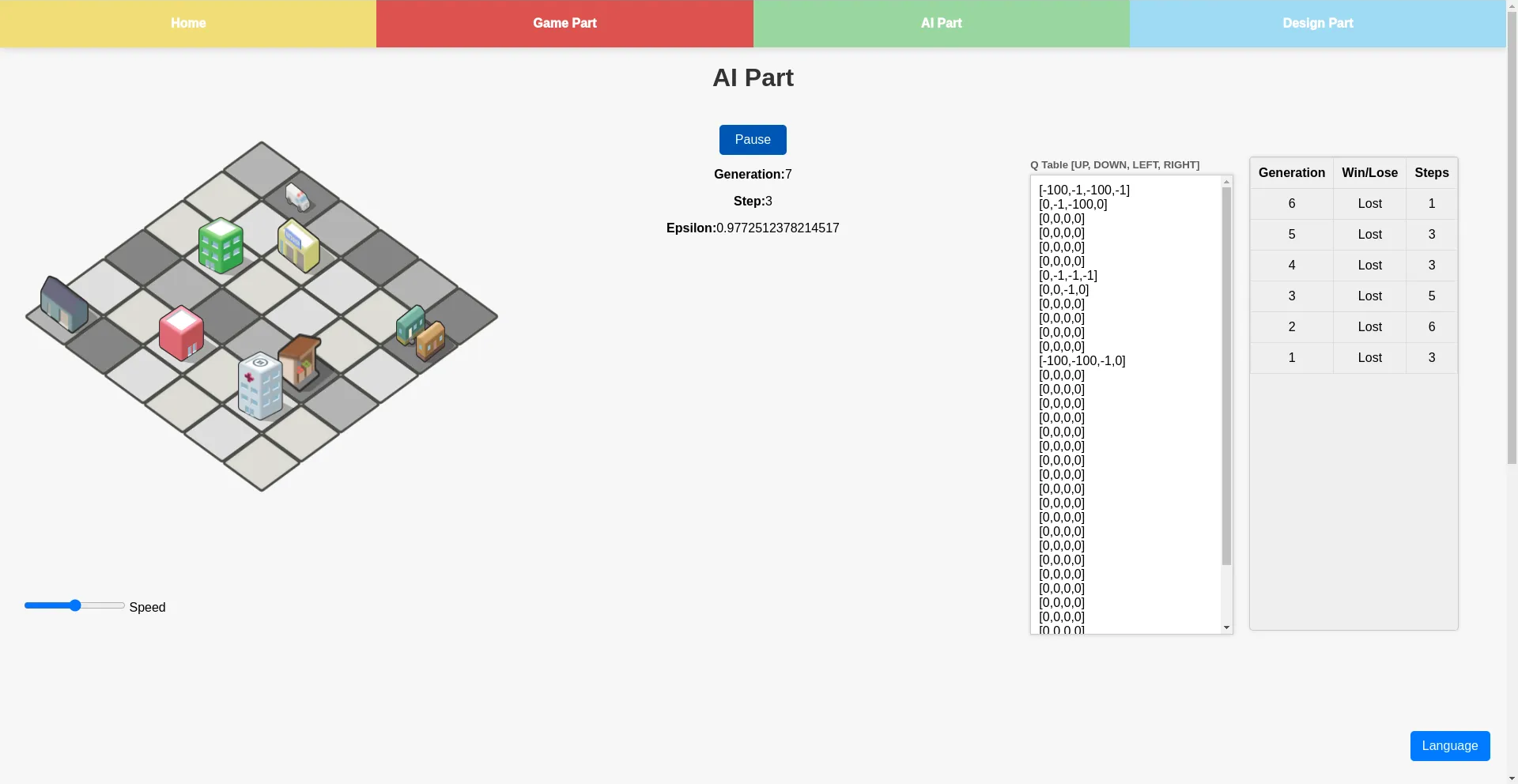
L'enseignant doit les encourager à faire des observations spécifiques et détaillées concernant le processus d'apprentissage de l'IA :
- Comparaison avec l'apprentissage humain : comment le processus d'apprentissage de l'IA se compare-t-il à sa propre expérience à l'étape 1 ? En quoi est-il similaire et en quoi est-il différent ? Discutez des similitudes et des différences dans les méthodes et l'efficacité de l'apprentissage.
- Observation par essais et erreurs : combien de tentatives l'IA a-t-elle dû effectuer avant de trouver l'objectif de manière fiable ? Quel rôle ont joué les renforcements positifs et négatifs dans l'orientation de ses décisions ?
- Optimisation du chemin : combien de temps faut-il à l'IA pour trouver un chemin optimal (le plus court) par rapport à la phase initiale d'exploration aléatoire ? Dans l'application BioLearning, les étudiants doivent observer les tentatives initiales où l'IA se déplace de manière aléatoire, sans aucune compréhension de l'environnement, puis noter l'amélioration progressive. Combien d'itérations ont-elles fallu avant que l'IA soit capable d'atteindre systématiquement l'objectif, et combien de temps avant de trouver l'itinéraire le plus efficace ?
- Effets de renforcement : Observez comment le renforcement positif (atteindre l'objectif) et le renforcement négatif (franchir des obstacles) influencent le comportement de l'IA. Quels modèles remarquent-ils dans la façon dont l'IA réagit à ces renforcements ?
- Adaptation et amélioration : comment l'IA s'adapte-t-elle au fil des générations d'apprentissage ? Quels changements de stratégie peut-on observer au fur et à mesure de son apprentissage ?
L'enseignant animera également des discussions sur les raisons pour lesquelles l'IA se comporte différemment des apprenants humains. Les élèves doivent être encouragés à réfléchir aux avantages de l'apprentissage informatique, tels que la rapidité et la capacité à tester de nombreux chemins sans fatigue, par rapport à l'adaptabilité et à l'intuition que les humains apportent aux tâches de résolution de problèmes.
En se concentrant sur ces questions, les étudiants comprendront mieux la nature systématique de l'apprentissage de l'IA, le rôle des essais et des erreurs et la manière dont les mécanismes de renforcement favorisent l'amélioration au fil du temps.
Restitution et réflexion
- Connaissances mobilisées : À la fin de cette étape, les élèves auront développé une compréhension fondamentale de l'apprentissage par renforcement et de son application dans les systèmes d'IA. Ils comprendront que contrairement aux humains, qui peuvent utiliser l'intuition et le contexte pour naviguer dans les situations d'apprentissage, les machines s'appuient sur un retour d'information systématique et de nombreuses tentatives pour construire un modèle fiable de leur environnement. Les élèves apprendront comment l'IA utilise l'apprentissage Q pour affiner de manière itérative ses décisions, ce qui conduit finalement à une stratégie améliorée en fonction des récompenses et des pénalités reçues.
- Réflexion sur le renforcement : Encouragez les élèves à réfléchir à la manière dont les renforcements positifs et négatifs ont façonné le processus d'apprentissage pour eux-mêmes et pour l'IA. Expliquez pourquoi le renforcement positif (par exemple, des récompenses pour avoir atteint l'objectif) et le renforcement négatif (par exemple, des pénalités pour avoir heurté des obstacles) sont tout aussi essentiels à l'apprentissage. Mettez en évidence l'idée que l'apprentissage, qu'il soit humain ou mécanique, nécessite à la fois des encouragements et l'identification des erreurs pour affiner la compréhension et améliorer les résultats au fil du temps.
- Le concept d'efficacité : expliquez comment l'objectif de l'IA a évolué au fil du temps, de la simple atteinte de la cible à la recherche du chemin le plus efficace pour y parvenir. Au départ, l'objectif de l'IA est d'apprendre à réussir, mais à mesure qu'elle acquiert de l'expérience, elle commence à optimiser son approche en recherchant des chemins plus courts et plus efficaces. Cela ressemble à la façon dont les humains affinent leur apprentissage pour devenir plus efficaces dans leurs tâches après avoir acquis une compréhension fondamentale. Soulignez que l'efficacité est souvent un objectif secondaire mais essentiel dans l'apprentissage humain et automatique.
- Comprendre l'amélioration itérative : Discutez avec les élèves de la manière dont l'IA améliore son modèle de manière itérative. Au début, elle se déplace presque de manière aléatoire, mais au fil des itérations successives et avec le renforcement des retours d'information, elle commence à prendre des décisions plus éclairées. Cela reflète le processus d'apprentissage humain où la pratique répétée mène à la maîtrise. Dans l'outil BioLearning, les élèves peuvent observer comment les chemins de l'IA sont initialement inefficaces mais deviennent progressivement plus directs à mesure que l'IA apprend des expériences positives et négatives.
- Comparaison entre l'apprentissage humain et l'apprentissage automatique : Animez une discussion sur les différences entre l'apprentissage humain et l'apprentissage automatique. Alors que les humains peuvent souvent faire des sauts intuitifs et s'adapter rapidement en fonction des expériences passées, les machines ont besoin de retours explicites et de nombreuses itérations pour apprendre. Soulignez que les humains peuvent généraliser d'une expérience à une autre beaucoup plus rapidement, tandis que les machines ont besoin de données systématiques et de renforcement pour construire leur modèle à partir de zéro. Cette comparaison aide les élèves à apprécier les forces et les limites uniques des deux types d'apprentissage.
- Résultats d'apprentissage généraux : À la fin de cette phase, les élèves devraient avoir une meilleure compréhension de la manière dont l'apprentissage par renforcement permet aux machines d'apprendre par l'expérience, et en quoi cela diffère fondamentalement de l'apprentissage humain. Ils comprendront que si les machines excellent dans le traitement de grands ensembles de données et peuvent effectuer des processus d'essais-erreurs exhaustifs sans fatigue, elles manquent de l'adaptabilité et de l'intuition inhérentes à l'apprentissage humain. À l'inverse, ils devraient reconnaître que les humains peuvent apprendre efficacement à partir d'un nombre réduit d'exemples en raison de leur capacité à s'appuyer sur des connaissances préalables et une compréhension contextuelle. Encouragez les élèves à réfléchir à la manière dont la combinaison de l'intuition humaine et de la puissance de traitement des machines pourrait conduire à de puissantes synergies dans la résolution de problèmes.
Pour conclure cette étape, les étudiants seront invités à discuter des questions suivantes :
- Comment l'approche d'apprentissage automatique se compare-t-elle à la vôtre à l'étape 1 ?
- Pourquoi pensez-vous que l'IA a eu besoin de plus ou moins de tentatives pour apprendre le bon chemin par rapport aux étudiants ?
- Selon vous, quelles sont les forces et les faiblesses de l'approche de l'IA en matière d'apprentissage ?
- Comment le concept de renforcement aide-t-il les humains et les machines à améliorer leurs performances ?
- Si l'objectif changeait, comment pensez-vous que la machine réagirait par rapport à un humain ?
- Comment l'IA a-t-elle géré les mouvements incorrects et comment a-t-elle utilisé ces informations lors des tentatives ultérieures ?
- Dans quelle mesure l'approche de l'IA est-elle bio-inspirée ? Comment imite-t-elle les processus d'apprentissage naturels ?
- Dans quelle mesure les essais et erreurs ont-ils été importants pour que l'IA trouve l'objectif, et pourquoi ?
- Que pouvons-nous apprendre sur l'adaptabilité humaine en la comparant au processus d'apprentissage de la machine ?
- Quels types de tâches pourraient être plus adaptés à l'apprentissage de l'IA qu'à l'apprentissage humain, et pourquoi ?
Étape 3 : Adaptabilité des humains par rapport aux machines
Contexte de la séquence
Dans cette dernière étape, les élèves exploreront l'adaptabilité des humains et des machines dans un environnement en évolution. Le défi est de comprendre comment les humains peuvent tirer parti de leur intuition, de leurs expériences antérieures et de leurs stratégies d'adaptation face à des changements inattendus, par rapport à une IA qui doit reconstruire son modèle à partir de zéro. Cette comparaison vise à mettre en évidence les forces et les faiblesses des deux types d'apprentissage.
Objectifs d'apprentissage
- Compétences de base : comprendre le concept d'adaptabilité dans l'apprentissage, comparer la flexibilité humaine avec les capacités d'apprentissage automatique et explorer comment les deux réagissent aux changements de leur environnement.
- Compétences auxiliaires : Développer la pensée critique en analysant les différences dans les stratégies d'apprentissage, améliorer les capacités de résolution de problèmes en naviguant dans un environnement modifié et s'engager dans un apprentissage collaboratif par le biais d'activités de groupe.
Conceptualisation
À ce stade, les élèves conceptualiseront le rôle crucial de l'adaptabilité dans l'apprentissage, que ce soit chez les humains ou chez les machines. L'accent sera mis sur la manière dont les humains utilisent leurs expériences passées et leur intuition pour ajuster leurs actions, par rapport au besoin de l'IA de reconstruire son modèle d'apprentissage face aux changements de l'environnement. Pour faciliter cela, les élèves travailleront en petits groupes pour définir ce que signifie l'adaptabilité dans les contextes biologiques et technologiques.
- Établir des hypothèses : les élèves commenceront par émettre des hypothèses sur la manière dont les humains et les machines pourraient s'adapter aux changements inattendus dans un environnement donné. Ils discuteront de questions telles que : « Comment une IA pourrait-elle réagir si l'emplacement de l'objectif change de manière inattendue ? » ou « Quelles stratégies les humains utilisent-ils lorsqu'ils se rendent compte que leur plan initial n'est plus efficace ? » Ces hypothèses serviront de base à l'expérimentation et à l'analyse ultérieure.
- Redéfinition de l'environnement : les élèves seront divisés en deux groupes. Le premier groupe modifiera la carte originale de la ville (représentant l'environnement de l'IA) en changeant le point de départ, en modifiant les obstacles ou en déplaçant l'objectif. Le deuxième groupe devra parcourir la carte modifiée, comme dans l'exercice initial. Les élèves ne pourront pas voir les changements à l'avance, ce qui simulera un changement inattendu de l'environnement.
- Comprendre les modèles d'apprentissage : les enseignants présenteront l'idée d'un modèle d'apprentissage pour les humains et les machines. Pour les machines, cela signifie recycler ou mettre à jour le modèle d'IA en utilisant de nouvelles données pour s'adapter aux changements, tandis que pour les humains, cela implique d'utiliser les expériences et d'appliquer les connaissances antérieures de manière intuitive. Les enseignants doivent souligner que l'IA a besoin d'un recyclage explicite, tandis que les humains s'adaptent souvent de manière plus fluide en utilisant leur intuition.
- Analyse critique : tout au long de cette étape de conceptualisation, encouragez les élèves à analyser de manière critique les différences entre l'adaptabilité humaine et l'adaptabilité des machines. Des questions telles que « Qu'est-ce qui rend les humains plus adaptables dans certaines situations ? » et « En quoi l'approche de l'IA diffère-t-elle fondamentalement de la prise de décision humaine ? » contribueront à approfondir leur compréhension.
Investigation par les élèves
Adaptabilité de l'humain
Dans la phase d'investigation, les élèves mettront leurs hypothèses à l'épreuve en s'engageant dans une activité pratique. Les élèves seront divisés en deux groupes, chacun ayant des rôles distincts pour simuler un environnement d'apprentissage dynamique :
- Groupe 1 : Concepteurs de cartes : Le premier groupe sera chargé de créer une nouvelle carte de la ville en modifiant l'emplacement des obstacles, en changeant le point de départ et en déplaçant l'objectif vers un autre emplacement. Ce groupe agira de la même manière que l'enseignant de l'étape 1, en donnant des instructions et en fournissant des commentaires. Au fur et à mesure que le jeu progresse, ils attribueront des récompenses et des pénalités en fonction des actions de l'autre groupe, imitant la façon dont l'IA a reçu des commentaires au cours de son processus d'apprentissage.
- Groupe 2 : Navigateurs : Le deuxième groupe sera chargé de naviguer sur la carte nouvellement modifiée. Ils tenteront de trouver le chemin optimal vers l'objectif en apprenant par essais et erreurs, en s'appuyant sur les commentaires donnés par le groupe 1. Leur tâche consiste à accumuler autant de points que possible tout en essayant de déterminer le meilleur itinéraire. En essayant successivement différents chemins, ils apprendront progressivement à identifier la stratégie gagnante et à chercher le chemin le plus court vers la cible.
Une fois l'activité terminée, les groupes échangeront les rôles. Cela donnera à tous les élèves l'occasion d'expérimenter les deux aspects de l'adaptabilité : apporter des modifications à un environnement et s'adapter à des changements inattendus sans connaissances préalables.
Adaptabilité de la machine
Après avoir terminé l'exercice pratique, les élèves procéderont ensuite à la modélisation de leur carte modifiée à l'aide de l'onglet « Conception » de l'application BioLearningGame. Ils saisiront les modifications qu'ils ont apportées pendant l'exercice pratique pour créer une version virtuelle de l'environnement. L'IA tentera ensuite de s'adapter à la nouvelle configuration, en démontrant comment elle aborde le problème par rapport aux apprenants humains.
Les élèves doivent observer attentivement la manière dont l'IA gère le nouvel environnement. Au début, l'IA sera peu performante, se déplaçant de manière aléatoire sans stratégie claire, de la même manière que le groupe 2 a initialement parcouru la nouvelle carte. Cependant, au fil des itérations, l'IA commencera à apprendre des commentaires qu'elle reçoit, pour finalement atteindre l'objectif.
Comparaison
L'un des enseignements clés que les étudiants devraient tirer de cet exercice est que l'IA a initialement appris un itinéraire spécifique vers l'objectif dans l'environnement d'origine. Lorsque la carte change, l'IA doit essentiellement réapprendre à partir de zéro, en le traitant comme un nouveau problème. Cela met en évidence une différence fondamentale entre l'adaptabilité humaine et celle des machines. Les humains sont capables d'utiliser leurs connaissances antérieures pour s'adapter relativement rapidement, tandis qu'une IA doit souvent réinitialiser son apprentissage et recommencer à zéro lorsqu'elle est confrontée à des changements environnementaux importants.
Cette phase d'investigation aidera les étudiants à développer une compréhension nuancée des limites de l'apprentissage automatique et à apprécier l'adaptabilité unique de la cognition humaine.
Conclusion et réflexion approfondie
- Connaissances mobilisées : À la fin de cette étape, les élèves auront une compréhension claire du concept d'adaptabilité, tant chez les humains que chez les machines. Ils reconnaîtront que si les humains peuvent s'appuyer sur leurs expériences antérieures et leur intuition pour s'adapter rapidement aux changements, les machines doivent systématiquement réapprendre lorsqu'elles sont confrontées à un environnement modifié. Cette distinction met en évidence les différents mécanismes sous-jacents à l'apprentissage humain et à l'apprentissage automatique, en soulignant la façon dont les machines s'appuient sur des processus de recyclage structurés par rapport à l'improvisation humaine et à l'adaptation basée sur l'expérience.
- Adaptabilité de l'humain et de la machine : Animez une discussion pour explorer la manière dont les humains ont réussi à s'adapter aux changements de l'environnement par rapport à la façon dont l'IA a réagi. Quelles différences les élèves ont-ils remarquées dans les stratégies d'apprentissage utilisées par les humains par rapport à la machine ? Discutez de la manière dont les humains ont pu utiliser leurs connaissances antérieures pour s'adapter plus efficacement, tandis que l'IA a dû en quelque sorte repartir à zéro pour apprendre le nouvel environnement.
- Renforcement et apprentissage itératif : renforcez le concept de renforcement positif et négatif dans les contextes humains et machines. Mettez en évidence la manière dont le groupe 2 (navigateurs) s'est appuyé sur les retours (récompenses ou pénalités) du groupe 1 pour améliorer progressivement son cheminement. Comparez cela avec la manière dont l'IA s'appuie sur les signaux de renforcement pour mettre à jour son modèle et trouver progressivement un itinéraire optimal. Soulignez comment l'apprentissage itératif, que ce soit par l'expérience humaine ou par le calcul machine, nécessite les deux types de renforcement pour guider efficacement le comportement.
- Limites et opportunités : Animez une discussion sur les limites et les atouts de l'apprentissage automatique. Pourquoi l'IA a-t-elle du mal à s'adapter aussi efficacement que les humains lorsque l'environnement change ? Quels sont les avantages d'avoir des machines capables d'effectuer des milliers d'itérations sans fatigue ? Encouragez les élèves à réfléchir aux améliorations potentielles des systèmes d'IA qui pourraient leur permettre de s'adapter de manière plus fluide, par exemple en conservant une certaine forme de connaissances généralisables au lieu de tout recommencer.
- Applications pratiques : Demandez aux élèves de réfléchir aux applications pratiques des concepts appris. Comment l'adaptabilité se manifeste-t-elle dans les systèmes d'IA du monde réel, tels que les logiciels de navigation, les véhicules autonomes ou les assistants personnels ? Quels sont les défis auxquels ces systèmes sont confrontés lorsque le contexte ou l'environnement change ? Cette discussion aidera les élèves à relier l'activité aux technologies du quotidien et à mieux apprécier la complexité de l'apprentissage automatique.
- Réflexion en classe : Enfin, donnez aux élèves l'occasion de réfléchir à leur propre expérience d'adaptation aux changements de la carte et de la comparer à la façon dont la machine s'est adaptée. Qu'ont-ils ressenti en devant trouver une nouvelle solution dans un environnement où les règles avaient changé ? Qu'ont-ils appris sur les différences entre les capacités de résolution de problèmes des humains et des machines ? Cette réflexion permet de consolider les objectifs d'apprentissage en matière d'adaptabilité, de pensée critique et de compréhension des mécanismes sous-jacents de l'apprentissage par renforcement chez les humains et les machines.
Pour aller plus loin
Exploration de la problématique au travers d'autres initiatives
- Comment les humains s'adaptent-ils aux changements inattendus différemment des machines ?
- Quel rôle joue l'expérience antérieure dans l'adaptabilité humaine et pourquoi est-elle un défi pour les machines ?
- Comment l'apprentissage par renforcement pourrait-il être amélioré pour permettre aux machines de s'adapter plus efficacement à de nouveaux environnements ?
- Pourquoi le renforcement positif et négatif est-il nécessaire dans les processus d'apprentissage ?
- À quels défis les systèmes d'IA sont-ils confrontés pour s'adapter à de nouvelles situations, et comment ces défis pourraient-ils être atténués ?
- Pouvez-vous penser à des exemples dans votre vie quotidienne où l'adaptabilité est importante ? Comment les humains gèrent-ils ces situations ?
- Comment l'incapacité d'une IA à généraliser à partir d'un apprentissage antérieur affecte-t-elle ses performances dans les applications du monde réel ?
- Quels sont les dangers potentiels des machines qui doivent réapprendre à partir de zéro à chaque changement de leur environnement ?
- Comment la créativité humaine et l'apprentissage automatique peuvent-ils se compléter pour résoudre des problèmes complexes ?
- Quel avenir pour les systèmes d'IA en termes d'amélioration de l'adaptabilité ? Quels sont les domaines qui nécessitent le plus d'attention en matière de développement ?
Bibliographie
Pour les enseignants souhaitant explorer plus en profondeur le concept d'apprentissage par renforcement et sa dimension bio-inspirée, les ressources suivantes sont recommandées :
Livres
- Apprentissage par renforcement : une introduction par Richard S. Sutton et Andrew G. Barto — Il s'agit d'une excellente ressource pour comprendre les fondamentaux de l'apprentissage par renforcement, avec de nombreux exemples démontrant comment un agent apprend par essais et erreurs.
- Le livre du pourquoi : la nouvelle science de la cause et de l'effet par Judea Pearl — Ce livre donne un aperçu de l'importance de la causalité dans l'apprentissage, y compris l'apprentissage par renforcement.
Articles académiques
- Un aperçu des techniques d'apprentissage par renforcement — Offre un large aperçu des différentes techniques et concepts associés à l'apprentissage par renforcement.
- Apprentissage par renforcement dans les systèmes artificiels et biologiques — Explore comment les techniques d'apprentissage par renforcement s'inspirent des modèles biologiques, notamment du comportement animal.
Cours en ligne
- Coursera — Principes fondamentaux de l'apprentissage par renforcement — Un cours interactif qui présente les concepts clés de l'apprentissage par renforcement, offert par l'Université de l'Alberta.
- edX — Intelligence artificielle (IA) — Ce cours général d'IA comprend une introduction à l'apprentissage par renforcement, expliquée avec des exemples pratiques.
Vidéos éducatives
- Apprentissage par renforcement profond : Pong à partir de pixels — Une vidéo qui illustre comment l'IA apprend à jouer à Pong, montrant comment le renforcement positif et négatif affecte les décisions d'un agent.
- Comment l'intelligence artificielle apprend-elle ? — Une courte vidéo captivante expliquant comment les machines apprennent, y compris les principes de l'apprentissage par renforcement.
Sites Web et blogs
- AI Unplugged — Rassemblez dans un seul document plusieurs activités débranchées et du matériel pédagogique sur l'intelligence artificielle.
- Machine Learning Unplugged — The Tech Interactive — Activité débranchée pour découvrir l'apprentissage automatique grâce à la reconnaissance visuelle.
- Blog OpenAI — Présente des articles éducatifs et accessibles expliquant l'apprentissage par renforcement et son utilisation dans le développement de l'IA avancée.
- Blog DeepMind — Explore comment l'apprentissage par renforcement est utilisé pour résoudre des problèmes complexes, en s'inspirant du fonctionnement du cerveau humain.
- Apprendre aux machines à se comporter : l'apprentissage par renforcement — Cet article fournit un point d'entrée pour toute personne intéressée par l'apprentissage par renforcement. Il fournit les fondamentaux nécessaires pour comprendre ce que sont les algorithmes d'apprentissage par renforcement et comment ils fonctionnent.
- Apprentissage par renforcement profond : Pong à partir de pixels — Cet article présente un exemple d'application d'apprentissage par renforcement profond en développant un agent capable de jouer à Pong.
Plateformes de simulation
- OpenAI Gym — Une plateforme qui permet aux enseignants et aux étudiants d'expérimenter l'apprentissage par renforcement dans des environnements simulés, offrant une expérience pratique.
- BioLearningGame — L'outil déjà mentionné dans l'activité, qui permet de visualiser comment un modèle de machine apprend à partir de zéro en utilisant un renforcement positif et négatif.
Ces ressources aideront les enseignants à approfondir leur compréhension de l'apprentissage par renforcement et de ses inspirations biologiques, leur permettant ainsi d'enrichir les activités proposées aux élèves.
- Discover AI — The map (versions élèves et enseignants, avec légende bâtiments / hôpitaux).
Cette fiche fait partie du projet SteamCity, financé par le programme Erasmus+. Contenu sous licence CC BY-SA 4.0.